{kind=link}
토픽 모델링은 텍스트 데이터에서 주제를 찾아내는 방법으로, 문서 집합에서 각 문서가 어떤 주제들로 구성되어 있는지를 파악하는 분석 방법론입니다. 여러 토픽 모델 중에서 LDA(Latent Dirichlet Allocation)와 Gensim은 대표적인 분석 방법론입니다.
1.LDA
- 기본적인 가정으로 각 문서는 여러 개의 토픽들의 혼합으로 이루어져 있으며, 각 토픽은 단어들의 확률 분포를 가지고 있다는 가정으로 분석됩니다.
- 모델은 주어진 문서와 단어들을 바탕으로, 각 문서가 어떤 토픽들을 얼마나 포함하고 있을지를 추정합니다.
- LDA는 Gibbs 샘플링과 같은 방법을 사용하여 문서와 단어들 간의 토픽 분포를 학습합니다.
1-1.LDA 주요 함수
사이킷런의 LatentDirichletAllocation가 LDA 토픽모델링 함수이며 주요 하이퍼파라미터는 아래를 참고하며 Sklearn에서 LatentDirichletAllocation 전문을 참고하면 더욱 자세한 사용법을 알 수 있다.
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components = 10,
max_iter=5,
topic_word_prior=0.1,
doc_topic_prior=1.0,
learning_method='online',
n_jobs= -1,
random_state=0)- n_components : 토픽의 수
- doc_topic_prior : 문서의 토픽 분포의 초기 하이퍼파라미터
- topic_word_prior: 토픽의 단어 분포의 초기 하이퍼파라미터
- max_iter: 학습 데이터에 대한 학습 횟수 (epoch)
- learning_method: 기본값은 batch, component를 업데이트 하는 방식을 의미하며, 데이타가 클 경우 online모드가 속도가 더 빠르게 진행한다.
- n_job: 본 모델을 수행함에 있어 사용되어질 프로세스 수. -1이면 모든 포로세스가 해당 작업을 위해 사용된다.
2.Gensim 특징
- Gensim은 토픽 모델링 및 자연어 처리를 위한 오픈 소스 라이브러리
- LDA뿐만 아니라 다양한 토픽 모델링 알고리즘을 구현하고 있으며, 특히 대량의 텍스트 데이터에 대한 효과적인 토픽 모델링을 제공합니다.
- Gensim은 문서와 단어를 벡터 형태로 표현하여 처리하며, LDA뿐만 아니라 Word2Vec, Doc2Vec 등 다양한 모델을 지원합니다.
- 사용자가 쉽게 텍스트 데이터를 처리하고 토픽 모델링을 수행할 수 있는 편리한 인터페이스를 제공합니다.
2-1.Gensim 절차
Gensim을 이용하여 Topic모델을 수행하기 위해서는 Dictionary, Corpus 그리고 이 두가지를 이용한 Model이 필요하다.
- Gensim은 먼저 토큰화 결과로부터 토큰과 gendim모듈이 내부적으로 사용하는 id를 매칭하는 사전을 생성: Dictionary 클래스 사용
- filter_extremes() 메소드에서, 사이킷런의 max_features에 해당하는 keep_n인수, min_df에 해당하는 no_below, max_df에 해당하는 no_above인수를 이용해 특성을 선택
- doc2bow()메소드로 토큰화된 결과를 카운트 벡터, 즉 BOW형태로 변환
- Gensim에서 LDA 모델을 수행하는 클래스인 LdaModel 시행
- num_topics : 토픽의 수
- id2word : Dictionary를 의미
- passes : 사이킷런의 max_iter와 같다고 보면 됨, 학습하는 횟수를 지정한다.
- 더욱 정확한 내용은 GENSIM 공식 싸이트를 확인하는 것이 좋다.
from gensim.corpora.dictionary import Dictionary
from gensim.models import LdaModel
# 토큰화 결과로부터 dictionay 생성
dictionary = Dictionary(sentences_list_word)
print('#Number of initial unique words in documents:', len(dictionary))
# 문서 빈도수가 너무 적거나 높은 단어를 필터링하고 특성을 단어의 빈도 순으로 선택
dictionary.filter_extremes(keep_n=2000, no_below=5, no_above=0.5)
print('#Number of unique words after removing rare and common words:', len(dictionary))
# 카운트 벡터로 변환
corpus = [dictionary.doc2bow(text) for text in sentences_list_word]
print('#Number of unique tokens: %d' % len(dictionary))
print('#Number of documents: %d' % len(corpus))
num_topics = 10
passes = 5
%time model = LdaModel(corpus=corpus,id2word=dictionary,passes=passes,num_topics=num_topics,random_state=7)3. 토픽의 수 결정
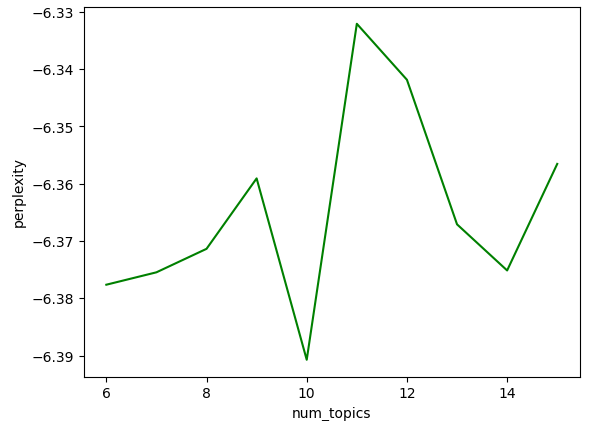
3-1.혼란도(혼잡도)-Perplexity
- 확률 모형이 실제로 관측되는 값을 얼마나 유사하게 예측해내는지를 평가할 때 사용한다.
- 문서 집합을 얼마나 유사하게 생성할수 있는지 나타낸다고 해석 가능
- 값이 작을수록 좋다.
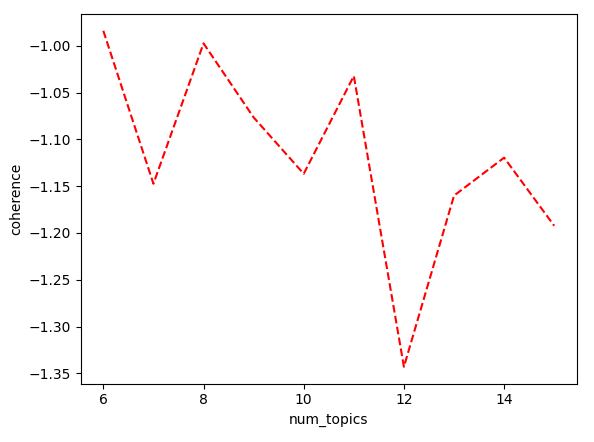
3-2.응집도-Cohence
- 각 토픽에서 상위 비중을 차지하는 단어들이 의미적으로 유사한지를 나타내는 척도
- 만일 토픽이 단일 주제를 잘 표현한다면 의미적으로 유사한 단어들의 비중이 높을 것이라는 가정에 성능을 표현한다.
- 값이 클수록 좋다.
아래와 같이 Perplexity는 토픽수가 10인 경우, Coherence는 6이 좋은 경우는 어떻게 해야 할까? 적정선에 대한 토픽은 분석가에 의해 결정된다 할 수 있다. 이런 이유로, 두가지 지표는 좋은 참고용으로 삼고 실제적으로 결과로 도출된 토픽의 내용을 확인할 필요가 있다.